 We have mentioned either directly or in passing in previous analysis blogs that we're always on the lookout for opportunities to harness the latest AI tools within our systems and see how they shape up. We've made a big change to our own internal CRM along these lines. We've added some new code that allows AI tools like Claude to connect to it so we can then "talk" to the database in natural language.
We have mentioned either directly or in passing in previous analysis blogs that we're always on the lookout for opportunities to harness the latest AI tools within our systems and see how they shape up. We've made a big change to our own internal CRM along these lines. We've added some new code that allows AI tools like Claude to connect to it so we can then "talk" to the database in natural language.
The technical name for what we've built here is an "MCP Server". This exposes the data in our system in a way that AI tools understand, and it can then run queries on it using those tools to find out the answers to the questions that are being asked. Here's an example of it in action:
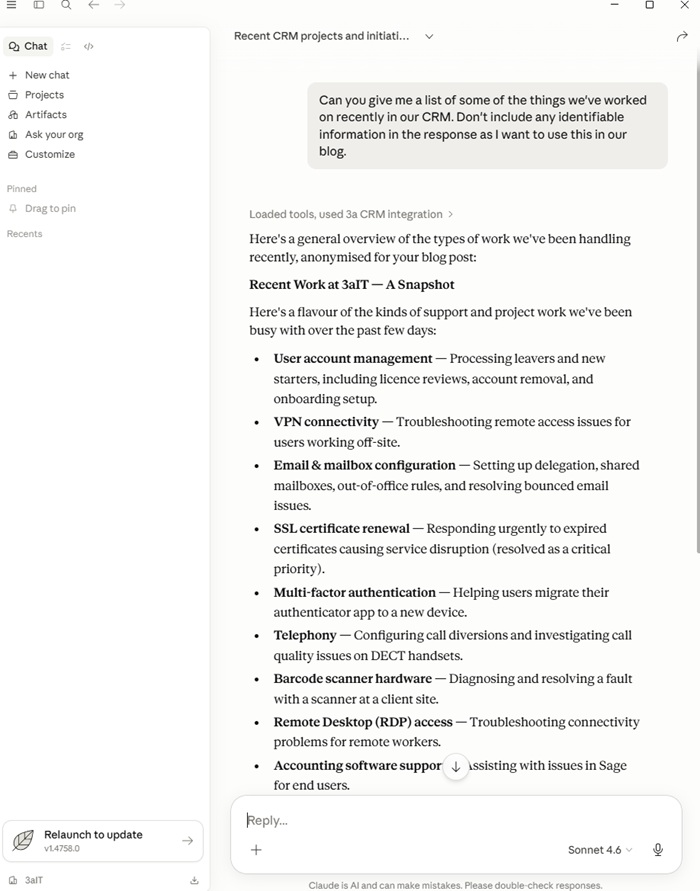
We've used Claude Desktop there, but other AI systems like ChatGPT and CoPilot can do exactly the same thing (and, indeed, we've also got CoPilot connected to it as well in an effort to try and see if we can create a "Support Bot" that we can use internally based on our solution-rich database).
As you can see above, it's clearly working fine in general. You'll have to take our word for it that it's also working specifically. It can delve into the detail of specific logs and suggest answers or alternative approaches if necessary.
The area it seems to have most utility (for our own system, at least), is for "fuzzy" searching. This is when you're searching for something "along the lines" of an idea. As you might expect, our system does have its own internal search, and this works exactly as you might expect. If you search for "VPN", it will give you every log that mentions a VPN over the 25 years of data we have stored. You won't be surprised to hear that's a lot of logs. Using a tool like this helps to reduce that noise. You can provide wider context and a much more intelligent search will be done.
So far so good. However, before you all bash down our door asking for something similar, it's worth delving a little deeper.
 The first thing that should be said here is that the data our system stores is particularly suited to this sort of thing. We deal almost entirely in tickets and logs. This means our data is largely paragraphs and paragraphs of text written by us. Exactly the sort of thing these systems are good at analysing. Acres of high quality textual information.
The first thing that should be said here is that the data our system stores is particularly suited to this sort of thing. We deal almost entirely in tickets and logs. This means our data is largely paragraphs and paragraphs of text written by us. Exactly the sort of thing these systems are good at analysing. Acres of high quality textual information.
If you have a system that deals in numbers rather than text, then linking it up to your data would be more of a data analysis exercise than a search tool. It can absolutely do this too, but it's worth us giving you an example from one of our experiments here.
In one test, we asked it to give us a graph of time worked on a particular client between January and March. It then went off, crunched the numbers, and gave us exactly that. Except... something didn't look quite right for March to us. It was far lower than we expected. We then questioned it some more, and it turned out it hadn't actually grabbed all the data for March and had just "guessed" at what it might be. It then went off and found tens of hours it hadn't included previously.
Now, it could well be we could tweak the code to ensure this specific issue doesn't occur again, but that's sort of by-the-by. The issue is more that it very confidently gave only a partially correct answer to our question (Jan and Feb were fine). It's only because we're very familiar with how the data should look that we spotted the problem.
So our current opinion on whether something like this could and should be used for data analysis is yes, but with huge amounts of care and attention, and a healthy scepticism about the answers being provided. It is likely it will work well for very targetted questions about a small set of data. The wider the scope of the question, the more likely it is to have just ignored some of the data it should have been sampling.
As ever, these things are rapidly evolving, so the issues we've noted here may be a thing of the past before too long. We'll be continuing to keep a very close eye on developments here, as always.